An AWS Event Sourcing architecture with DynamoDB
About
This article describes an event sourcing architecture built on AWS DynamoDB as an event log.
What is Event Sourcing
Event Sourcing is a design pattern that stores the state of an application as a sequence of immutable events. This differs from most applications and CRUD apps which only store the current state of the data.
In an event sourced system the current state of a system can be represented as below; Haskell syntax is used for brevity. Given a function f that takes an initial state and an event then applies the event to that state returning a new state, fold over all the given events with an initial state and return a final state.
currentState :: (state -> event -> state) -> state -> [events] -> state
currentState f events initialState =
loop events initialState
where
loop (x :: xs) state = loop xs (f state x)
loop [] state = stateThe above may look like a left fold that is because it is a left fold: foldl :: (a -> b -> a) -> a -> [b] -> a. See Fold (higher-order function) for more information if you are unfamiliar with this.
A trivialized example

- We have the type
Counter Intwhich stores an accumulated value. - We have a sum type
Event = Increment | Decrement - Given the events
[Increment, Increment, Increment, Decrement]and an initialCounter 0we should end up with a valueCounter 2after applying the events.
data Counter = Counter Int
data Event = Increment | Decrement
currentState :: Counter -> [Event] -> Counter
currentState initial events =
foldl f initial events
where
f (Counter n) Decrement = Counter (n - 1)
f (Counter n) Increment = Counter (n + 1)
events = [Increment, Increment, Increment, Decrement]
initialState = Counter 0
-- Run the assertion
assert (currentState initalState events) (Counter 2)A more in-depth explanation about Event Sourcing can be found at Martin Fowler’s Event Sourcing blog post.
An Event Sourcing architecture on AWS
Architecture overview
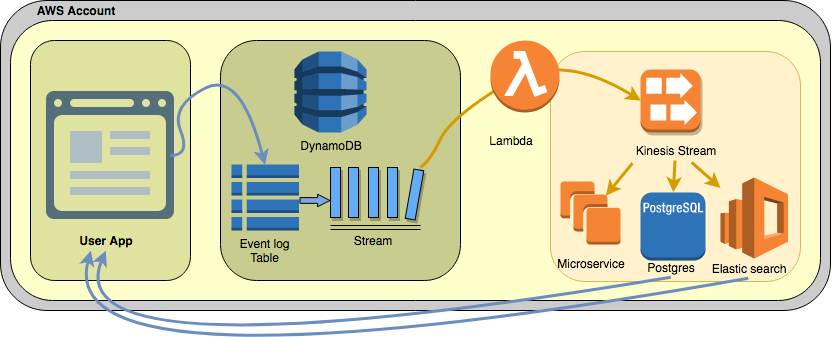
Event log / journal
DynamoDb is used to store the event log / journal. Using DynamoDB to store events is a natural fit on AWS although care needs to be taken to work within the DynamoDb constraints.
Why use DynamoDB
- Consistent low-latency response times
- Durability and resiliency, data is stored across three availability zones automatically
- DynamoDB exposes an event stream that can be subscribed to. This is a desirable feature as covered later
- DynamoDB now supports autoscaling of read / write throughput for cost optimization
- Guaranteed ordering across partitions when using a partition and sort key important
- IAM can be used to enforce the event log is append only
- No limits on the storage size of a given table
- Read and writes can be scaled separately to accommodate end access patterns
DynamoDB considerations
- Design to avoid hot aggregates to fully utilize provisioned throughput.
- Hydration, full rebuild of read stores will likely require increased read units during rebuild to avoid DyanmoDB throttling.
- The maximum row/item size in DynamoDB is 400 KB
Schema design
DynamoDB is a NoSQL Document store. To store events the below implicit schema can be used for the
EventLogtable:Attribute Desc ID UUID as the aggregate ID (Partition Key) Sequence Monotonic increasing integer storing the aggregate version number (Sort key) Event Serialized JSON blob containing the given event Timestamp UNIX epoch timestamp of the time the event was created Below is an example of how this may look populated with events where the aggregate is a
User.ID Sequence Event Timestamp 44ADBC2B-20ED-4DE8-8F13-89EE031DD3EA 0 { “event”: “User.Registered”, “version”: “V1”, “data”: { “username”: “admin”, “password”: “some-hash”, “email”: “example@example.com” } } 1511950291651 66A0864C-20BD-4CF1-8358-44D283B0576E 0 { “event”: “User.Registered”, “version”: “V1”, “data”: { “username”: “test”, “password”: “some-hash”, “email”: “test@example.com” } } 1511950839289 44ADBC2B-20ED-4DE8-8F13-89EE031DD3EA 1 { “event”: “User.UpdatedEmail”, “version”: “V1”, “data”: { “email”: “new.email@example.com” } } 1511950861793 44ADBC2B-20ED-4DE8-8F13-89EE031DD3EA 2 { “event”: “User.UpdatedPassword”, “version”: “V1”, “data”: { “password”: “new-password-hash” } } 1511950999233 Event envelope
From the above example we can see the event data is serialized in an envelope:
{ "event": "", "version": "", "data": {} }eventis an identifier used by the deserializer to detect what kind of event the item isversionis an identifier to indicate the version of the event. This is useful if you have an existing event type and would like to change it, giving the event a version allows to change how events look other time.datathis is the actual event data
eventandversioncould of been stored as separate attributes in the table- Placing them in the envelope allows pushing the
eventattribute to an event bus with all data and minimal effort to be consumed by other services. If additionally data is added to the envelope it automatically get pushed where as attributes we would need to update the streaming layer as well as the event envelope. - Instead of using JSON as the serialization format for the
eventfield Avro or Protocol Buffers may be used which allow us to apply a schema against events. I would highly recommend considering these as the binary format will help reduce record size when which is important with DynamoDB 400KB row size limit. Avro and Protocol Buffers also have built in functionality for handling versioning, the other advantage it it’s easier to distribute event schemas. For the post we use JSON as it’s will be familiar to most people. - I believe this to be the most flexible for change / exporting events
In practice the envelope can also contain other meta data such as
userthe user the event originated fromipaddress if a HTTP application and you need to keep audit history- etc
Event Bus
DynamoDB exposes a stream api to capture changes on a table. This is perfect for exposing an event bus and building a decoupled architecture where consumers (additional services) subscribe to the bus and react to events they are interested in asynchronously.
An example based on the previous user aggregate may be a email service listening for User.Registered events and sending a welcome email message.
Another example shown in the architecture diagram are services listening for events and writing the data in to an optimized read/query store such as Postgres or Elasticsearch. This is described more later in Read store / snapshot storage.
DynamoDB stream restrictions
Unfortunately DynamoDB streams have a restriction of 2 processes reading from the same stream shard at a time, this prevents the event bus architecture described above where it is likely many consumers would need to describe to the stream.
Kinesis
What is Kinesis
Amazon Kinesis Data Streams is a service build to allow applications work with streaming data.
- Unlike DynamoDB streams Kinesis does no have a restriction on the number of consumers. * There are restrictions on size of data. I recommend reading A month of Kinesis in Production blog post with details on some Kinesis quirks.
- Kinesis allows message acknowledgments (commits) so consumers can read from the last point in the stream they last read from
- Kinesis offers up to 7 days data retention policy for messages on a stream allowing consumers to carry on where they left off after downtime
- Guaranteed ordering of messages based on stream partition key.
- At least once messaging schematics
Note it is best to design events consumed from the bus to be idempotent.
Integrating with DynamoDB streams
The simplest way to integrate DynamoDB Streams with Kinesis is to use a Lambda function to take Dynamo events and push to Kinesis (Using AWS Lambda with Amazon DynamoDB)
An example Lambda is below, make sure the correct IAM roles are set up for the Lambda to be able to write to Kinesis.
var AWS = require('aws-sdk'); var kinesis = new AWS.Kinesis({ apiVersion: '2013-12-02' }); exports.handler = function(event, context, callback) { var kinesisStream; if (!process.env.KINESIS_STREAM_NAME) { console.error("Exiting: missing KINESIS_STREAM_NAME environment variable"); callback({reason: "Missing KINESIS_STREAM_NAME environment variable"}); } else { kinesisStream = process.env.KINESIS_STREAM_NAME; } if (event.hasOwnProperty('Records')) { // Collect DynamoDB INSERT events (event streaming is append only) var insertEvents = event.Records.filter((record) => { if (record.eventName === "INSERT" && record.eventSource === "aws:dynamodb") { return true; } else { console.log("Skipping " + record.eventName + " event from " + record.eventSource); return false; } }); // Messages to send to Kinesis var kinesisMsgs = insertEvents.map((record) => ({ Data: JSON.stringify(record.dynamodb.NewImage), PartitionKey: record.dynamodb.Keys.Id.S, SequenceNumberForOrdering: record.dynamodb.Keys.Sequence.N, StreamName: kinesisStream })); var counter = 0; kinesisMsgs.forEach((msg, i, arr) => { kinesis.putRecord( msg, (err, data) => { if (err) { console.error({ reason: "Failed to send msg to Kinesis", msg: msg, underlying: err }); } else { counter++; if (i === arr.length - 1) { console.log("Submitted " + counter + " messages to " + kinesisStream); callback(null, "Submitted " + counter + " messages to " + kinesisStream); } } } ); }); } else { console.error({ reason: "No `Records` value in event JSON", event: event }); callback({ reason: "No `Records` value in event JSON", event: event }); } };Note: In the above Lambda we drop messages on error. Also BatchPut is not used for simplicity as with BatchPut you need to manually check the success / failure status of each message in the batch and handle the retry logic manually. In a high throughput scenario batchput would be recommended. Dropping messages this way should not be a issue if consumers are aware of the last sequence number received for a aggregate id (partition key) and have logic to get any missing events directly from the event log. In a production environment error threshold monitoring and alarms would be enabled to detect a sudden spike of dropped messages indicating an error. It’s also worth triggering threshold alarms on a drop of message throughput indicating a error in the lambda receiving sending messages.
Read store / snapshot storage
Querying the event log is expensive computationally and with DynamoDB there is also a financial cost based on the consumed read units.
With the architecture outlined CQRS Command Query Responsibility Segregation is a natural fit. CQRS splits the write side of an application from the read side.
Whereas in a typical application you may have a *Service with CQRS you would have a *ReadService and a *WriteService.
In the event sourced architecture defined all writes go to the event log as immutable events. When the events are propagated to the event bus consumers listen for them and write them out for example to Postgres or Elasticsearch.
This provides some nice properties:
- We do not need to build the current state of the system each time the app starts up
- We can store the data in a database / search index optimized for how the application reads it preventing complex slow queries
- We can have many de-normalized views of the date based on the above optimized for specific user cases
- We can pick the data store optimal for the read / query usage of the data
- We can update, migrate and re-build the read stores at anytime as application requirements develop by replaying the event log
Some general principals should/must be followed:
- Applications should only read from the read store, they should never update the data directly
- Any writes / updates must be written to the event log only and event bus consumers propagate the changes to the read stores
- The system must be designed around eventual consistency. This means avoiding (not) writing data followed by a database query reading it straight back. Generating a client side UUID almost always avoids this.
Optimistic concurrency control
Event sourcing is based on building the state of the world based on a ordered sequence of events. For the state to be correct it is important that the ordering of events is enforced.
Based on the current design we can use optimistic concurrency control to enforce consistency.
HTTP optimistic concurrency control example
HTTP provides functionality to enforce optimistic concurrency schematics using the ETag: <value> header and If-Match: <etag_value> conditional header. This will be demonstrated using an example CRUD REST API with the event sourced architecture that has been described. The API will be based around todo messages.
Create
- Body:
{"id": "D8E8B51E-0337-4300-B414-0CC65918AAF8", "title": "TODO", "message": "Make coffee"} - Content-Type: application/json
- Method: POST
- URI:
/todo
Below is a sequence diagram of the request flow
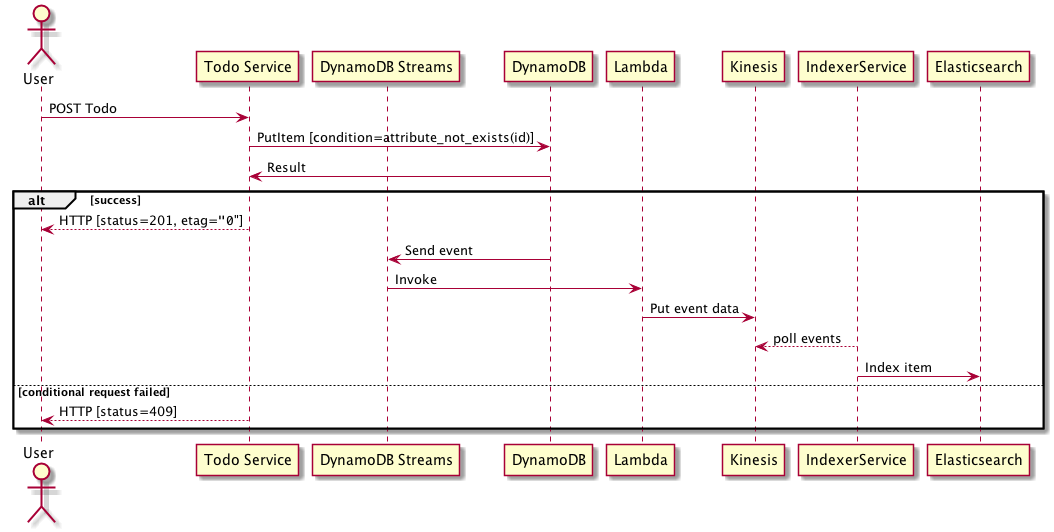
- The user makes a POST request with the todo message including a client side generated random UUID.
- The services makes a Conditional PutItem request to DynamoDB with a
attribute_not_exists(Id)constraint andSequencevalue of0. Theattribute_not_existsensures a item with the givenIdprimary key andSequencesort key does not exist or else it returns an error. - If the PutItem request is successful a 201 response is returned to the user as well as the sequence number in the etag. The item also propagates out to Kinesis via DynamoDB streams and Lambda asynchronously, the IndexerService maintains the latest materilized state of the todo item.
- If the PutItem fails with a condition error because the id already exists a 409 conflict error is returned
- Body:
Get
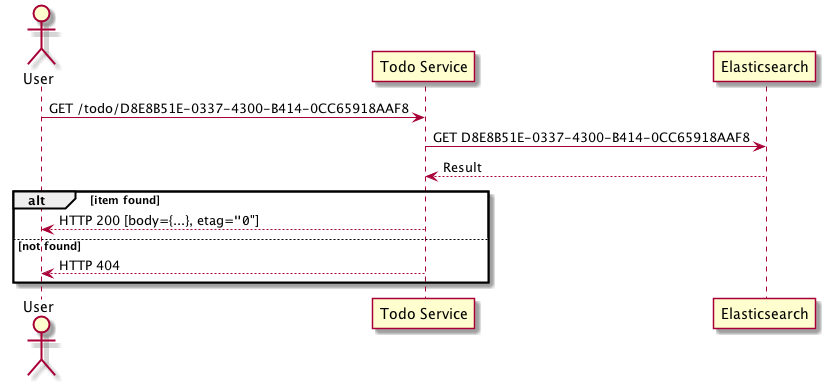
Get is interesting. The implementation of get has two potential options:
- Query all events for the aggregade id in the DynamoDB event log
- Query a readstore, Elasticsearch in this case
Querying the DynamoDB event log may be expensive if an aggregate id has hundreds / thousands of events which need to be replayed to build the current state.
In the design used here Elasticsearch always maintains the current state which allows for more efficient querying however as the system is eventually consistent the data may be stale for a short period of time.
As the system is designed to be eventually consistent stale data is acceptable for this use case. There is no right or wrong here and both are valid options, the choice should be made based on system requirements. Here Elasticsearch is used to demonstrate using an optimized readstore for querying.
In both cases it is important an
etagheader is returned in the response with the current sequence number.Update
- Body:
{"title": "TODO", "message": "Make 2 coffees"} - Content-Type: application/json
- Headers:
[If-Match="0"] - Method: POST
- URI:
/todo/D8E8B51E-0337-4300-B414-0CC65918AAF8(id)
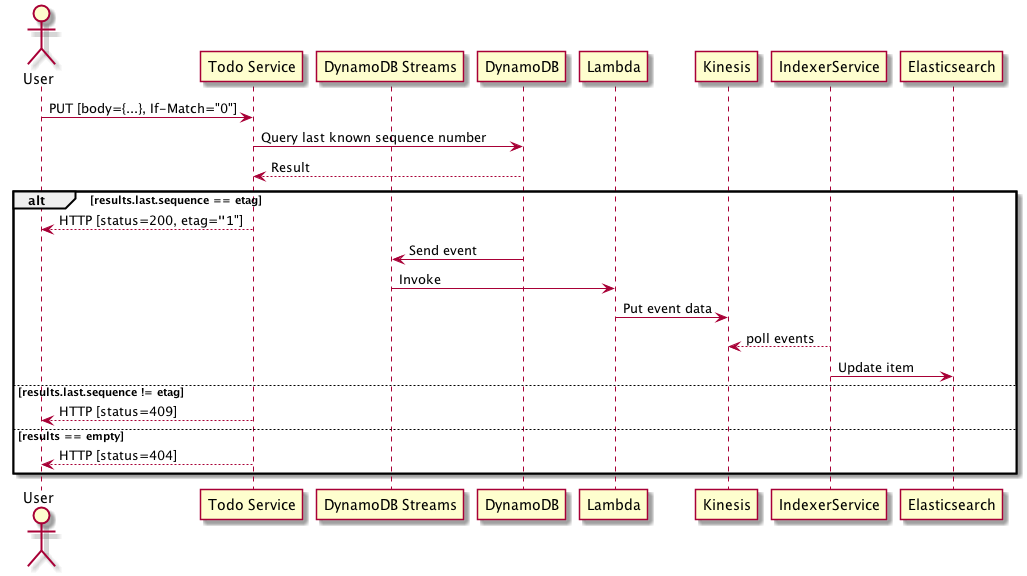
Update is a little more complicated.
When an update request is made an
If-Matchheader needs to be provided containing the version / sequence number of the item being updated. This value is provided in theGETETagrequest header from previous requests.- The service then performs a DynamoDB query to find the last known sequence number for the aggregate id / partition key. The following query constraints should be set:
- ConsistentRead
true, use strongly consistent reads for the query. - Limit
1, return only one result, i.e the first value found. - ProjectionExpression
Sequence, only return theSequencecolumn/value in the result set to save bandwidth. - ScanIndexForward
false, order by the secondary key descending,Sequencein our case.
- ConsistentRead
As a DynamoDB JSON request this would look like:
{ "TableName": "EventLog", "Limit": 1, "ConsistentRead": true, "ProjectionExpression": "Sequence", "KeyConditionExpression": "ID = :id", "ExpressionAttributeValues": { ":id": { "S": "D8E8B51E-0337-4300-B414-0CC65918AAF8"} } }- The service then validates the last known sequence number against the value in the
If-Matchheader:- If the last known sequence number matches the
If-Matchvalue perform a conditional put using theattribute_not_exist(Id)condition and incrementing the Sequence number. This will enforce uniqueness on theIdandSequencekey as they are set as thePrimaryandRangekeys. This may return aConditionalCheckFailedExceptionas someone may of beat us on aPutrequest between the time of querying the last known sequence number so the error case should be handled asking a user to load any changes and then merge in their updates before attempting to save again. - If the last known sequence number does not match the
If-Matchvalue return a HTTP409 Conflictresponse - If the query returned no results return a HTTP
404 Not Foundresponse, a non existent aggregate is attempting to be updated.
- If the last known sequence number matches the
- Body:
Delete
- Headers:
[If-Match="0"] - Method: DELETE
- URI:
/todo/D8E8B51E-0337-4300-B414-0CC65918AAF8(id)
Delete is essentially the same as Update with an empty body:
- Check the last known sequence number matches the value in the
If-Matchheader. On miss-match return a409, on a empty result set return404 - If the
If-Matchvalue matches the last known sequence perform a conditional PutItem request as Update however the event would beTodo.Deletedin our example case with an empty body.
Note we do not actually delete any data we simply mark the data as deleted in the event log, this is important Accountants Don’t Use Erasers. Read stores will then receive the
Deleteevent and delete related data from the readstore.- Headers:
Summary
This post has shown a high-level architectural design for event sourcing in AWS using DynamoDB as an event log. DynamoDB guarntees ordering across aggregate’s using a sort key which makes it possible to use it as an event store. For the curious other cloud based NoSQL databases on Azure and Google do not support the same ordering guarantees which make them unsuitable for event stores making DynamoDB unique for this usecase.